Day 20|她真的會「說」了:用免費 gTTS 讓 LINE Bot 說話(取代/備援 OpenAI TTS)
TL;DR
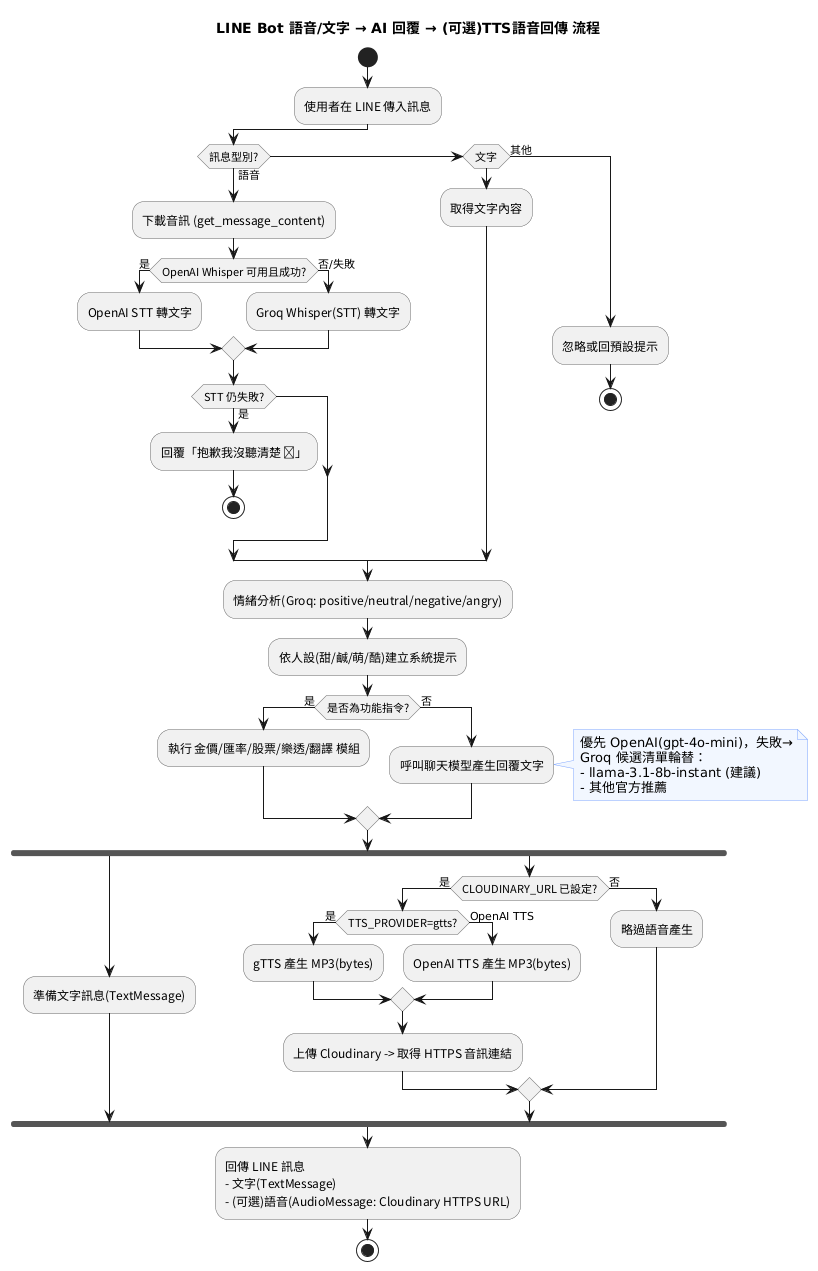
今天把昨天做好的「錄音→轉文字→AI 回覆」再升級:讓 AI 回覆同時也能「說出來」。不想燒金流?我們用 免費的 gTTS(Google Translate 的語音合成程式庫)當 主要或備援 TTS,產生 MP3 後丟到 Cloudinary 取得公開網址,再用 LINE AudioMessage 回傳。整套流程免刷卡、可直接部署在 Render。
⸻
我們要完成什麼?
• ✅ 把回覆文字轉成語音(TTS),讓機器人除了打字,也能說話
• ✅ 不依賴付費 API:導入 gTTS(免費)
• ✅ 若你同時有 OpenAI:支援 OpenAI TTS → gTTS 的自動備援
• ✅ 與既有架構銜接(Cloudinary 上傳 → LINE 回傳 AudioMessage)
• ✅ 提供完整程式片段+部署清單
⸻
為什麼選 gTTS?
• 免費、零申請:直接 pip install gTTS 可用
• 多語支援:包含 zh-TW、ja、en…
• 相容我們現有流程:輸出 MP3 → 上傳 Cloudinary → LINE 播放
• 小提醒:
• gTTS 是呼叫 Google Translate 的服務,偶爾會被限流,加上備援最穩(ex: 有 OpenAI TTS 就優先用,失敗再用 gTTS)
• 聲音自然度不如商業 TTS,但成本=0,上線超快
⸻
環境變數 & 專案設定
1. Cloudinary(必須)
確保你有 CLOUDINARY_URL,例如:
cloudinary://<api_key>:<api_secret>@<cloud_name>
2. (可選)OpenAI
若想保留 OpenAI TTS 作為主用或備援:
OPENAI_API_KEY=sk-xxxx
3. 新增一個小開關(可選):
TTS_PROVIDER=gtts # gtts / openai / auto(預設 auto:先 OpenAI 後 gTTS)
4. requirements.txt 新增(或確認):
gTTS
cloudinary
(你專案已含 cloudinary;若尚未加,記得補上)
⸻
代碼改造:把 gTTS 接上你的 Bot
下方片段可直接套進你目前的 app_fastapi.py(你 Day 18~19 版基礎已具備錄音→轉文字、Cloudinary 上傳、LINE 回傳音訊等流程)
在 imports 區塊新增:
from gtts import gTTS
在環境變數區塊補一個 TTS 選擇器(可放在你讀 OPENAI_API_KEY 的附近):
TTS_PROVIDER = os.getenv("TTS_PROVIDER", "auto").lower() # auto / openai / gtts
在你目前的 TTS 區塊旁(有 _create_tts_with_openai_sync 的地方)加上 gTTS 實作:
def create_tts_with_gtts_sync(text: str) -> bytes | None:
"""
使用 gTTS 生成語音(免費)。
回傳 MP3 bytes;失敗回 None。
"""
try:
# 去除一些 Markdown 符號,避免念出奇怪字元
clean_text = re.sub(r'[*`~#]', '', text).strip()
if not clean_text:
clean_text = "嗨,我在這裡。"
# zh-TW(正體中文),並使用台灣網域改善口音
tts = gTTS(text=clean_text, lang="zh-TW", tld="com.tw", slow=False)
buf = io.BytesIO()
tts.write_to_fp(buf)
buf.seek(0)
return buf.read()
except Exception as e:
logger.error(f"gTTS 生成失敗: {e}", exc_info=True)
return None
把你原本的 text_to_speech_async 改成會依 TTS_PROVIDER 選擇來源,失敗就自動換另一個:
async def text_to_speech_async(text: str) -> bytes | None:
"""
依照 TTS_PROVIDER 決定用哪個 TTS。
- auto: 先 openai 後 gtts
- openai: 只用 openai
- gtts: 只用 gtts
"""
provider = TTS_PROVIDER
async def try_openai():
return await run_in_threadpool(_create_tts_with_openai_sync, text)
async def try_gtts():
return await run_in_threadpool(_create_tts_with_gtts_sync, text)
if provider == "openai":
return await try_openai()
if provider == "gtts":
return await try_gtts()
# auto:先 OpenAI(若有)再 gTTS
if openai_client:
b = await try_openai()
if b:
return b
return await try_gtts()
你現在的回覆流程中,已經有:
• 文字回覆 → TextMessage
• 產生音訊 bytes → 上傳 Cloudinary → AudioMessage
不用大幅更動,只要 text_to_speech_async 回傳 bytes,後續就能沿用你原本的上傳+回傳程式碼。
⸻
完整回覆流程(示意)
1. 使用者說話或打字
2. (語音)→ Whisper 轉文字(OpenAI / Groq)
3. 建立人設+情緒 → LLM 生成回覆文字
4. 回覆文字 → 呼叫 text_to_speech_async():
• TTS_PROVIDER=auto:先 OpenAI,失敗以 gTTS 備援
• 或 TTS_PROVIDER=gtts:只用 gTTS
5. 成功產出 MP3 bytes → Cloudinary 上傳 → 取得 secure_url
6. LINE 回兩則訊息:
• TextMessage(文字)
• AudioMessage(音訊)
⸻
部署與測試
1. requirements.txt 加上:
gTTS
cloudinary
2. 設定環境變數(Render / Railway / Docker):
• CLOUDINARY_URL(必要)
• TTS_PROVIDER=auto(或 gtts)
• (可選)OPENAI_API_KEY(若你想主用 OpenAI 或保留備援)
3. 部署後在 LINE 丟一段文字:「今天有點累,安慰我一下」,看看能不能同時收到文字+語音。
4. 丟長一點的句子,觀察 gTTS 生成時間(長文會久一點,正常)。
5. 若音訊沒有出來:看 Render Logs 是否有 gTTS 或 Cloudinary 例外,再確認環境變數。
⸻
常見問題(FAQ)
Q1:LINE 一定要 M4A 嗎?我丟 MP3 可以嗎?
A:LINE 官方建議 M4A/AAC,但 MP3 一般也能播。為了簡化,我們用 MP3。若你想完全遵循建議,可加一個轉檔(ffmpeg)→ M4A 後上傳。
Q2:gTTS 聲音不夠自然?
A:免費方案的極限~若需要更自然的中文發音,可用 OpenAI / Azure / ElevenLabs 等商用 TTS(有費用)。我們的結構已可互換,只要改 text_to_speech_async 的產生器即可。
Q3:gTTS 會不會被限流?
A:有可能。建議保留 OpenAI 作備援,或在高流量場景加上簡單的去重/快取(同一句話先查快取,命中就直接回舊音檔)。
⸻
今日成果
• 完成 免費 TTS(gTTS) 整合
• 支援 OpenAI ↔ gTTS 自動備援
• 你的 LINE Bot 現在會聽、會想、也會說🎙️
⸻
接下來還可以優化的
• 快取與成本最佳化:文字→語音加上內容雜湊快取、Cloudinary TTL 與清理腳本
• 或:自動摘要語音訊息+「關鍵字抽取」與「待辦產生」